

|
Алгоритм
ZET |
|||||||||||||||||||||||||||||||||||||||||||||||||
|
Пусть задана
таблица экспериментальных данных Таблица экспериментальных
данных
где Ставится
задача восстановления отсутствующих (пропущенных) значений @ в таблице Рассмотрим решение поставленной задачи с помощью алгоритма ZET [1]. Данный метод относится к локальным методам заполнения пробелов, так как использует для нахождения решения только некоторую локальную часть экспериментальных данных. В основе его функционирования лежат три предположения (гипотезы): 1.
Гипотеза избыточности: предполагается,
что в таблице 2.
Гипотеза аналогичности: предполагается,
что если два объекта «похожи» по значениям ( 3. Гипотеза локальной компетентности: предполагается, что избыточность строк и столбцов носит локальный характер, то есть для каждого пропущенного значения имеется только некоторое количество объектов – аналогов объекта с пропуском и свойств – аналогов свойства с пропуском. Поэтому предлагается использовать для прогнозирования только такие «компетентные» объекты и свойства, которые выбираются для каждого пропуска отдельно. Основные этапы алгоритма ZET для обработки таблицы 1. Предварительная
обработка начальных данных. 2. Прогнозирование
пропуска - выполняется 2.1. Формирование
компетентной матрицы. 2.2. Подбор
параметров модели прогнозирования. 2.3. Прогнозирование
пропуска. Рассмотрим подробнее каждый этап. 1.
Вначале столбцы матрицы
2.
Следующие этапы выполняют 2.1. Формирование компетентной матрицы 2.1.1.
Задать размеры компетентной матрицы
2.1.2.
Выбрать Компетентность
где 2.1.3.
Выбрать Компетентность
где 2.2.
Подбор параметров моделей прогнозирования 2.2.1.
Задаем пределы изменения коэффициентов 2.2.2.
Находим оптимальные коэффициенты строкам и по столбцам по следующему алгоритму (одинаков
для строк и столбцов). Подавая значения коэффициента
где
где 2.3. Прогнозирование пропуска 2.3.1. Прогнозирование пропуска по столбцам выполняется по формуле
2.3.2. Прогнозирование пропуска по столбцам выполняется по формуле
2.3.3. Общий прогноз получается усреднением прогнозов по строкам и столбцам
Программы
заполнения пробелов могут работать в одном из следующих режимов:
1.
Заполнение всех пробелов в таблице по указанному алгоритму.
2.
Заполнение только тех пробелов, ожидаемая ошибка для которых
не превышает заданной величины. Для определения
ожидаемой ошибки предсказания вычисляется дисперсия значений подсказок
3.
Заполнение пробелов только на базе информации, имеющейся в
исходной таблице. 4.
Заполнение каждого следующего пробела с использованием исходной
информации и
прогнозных значений ранее заполненных пробелов. Список
использованных источников 1.
Загоруйко Н.Г. Методы распознавания и их применение. –
М.: Советское Радио, 1972. 2.
http://math.nsc.ru/AP/oteks/index.html. |
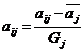 .
.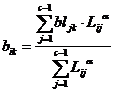 ,
,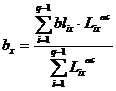 .
.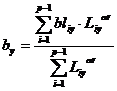 .
.