

|
Дистрибутивно –
лаговые модели (Часть 2) |
|
Дистрибутивно –
лаговые модели (Часть 2) В
предыдущем выпуске было рассмотрено три подхода к решению задачи упрощения
оценки параметров дистрибутивно-лаговых моделей:
где
где
где Все эти модели являются авторегрессивными и их можно
представить в виде Для оценки параметров Рассмотрим свойства
и соответственно
Для модели частичных приспособленностей Метод вспомогательных переменных. Для
того, чтобы избавиться от корреляции между
При использовании Так как Следует
отметить, что последовательные значения Примечание: каждый из трех методов должен использоваться для решения той или иной задачи исходя из его личных качеств и преимуществ на основе теоретических обоснований, а не только потому, что какая-то модель позволяет легче провести статистическую оценку. Определение автокорреляции в авторегрессивных моделях с помощью h-теста Дарбина. В
авторегрессивных моделях нельзя использовать d-тест Дарбина-Уотсона для определения серийной корреляции
первого порядка, так как d в таких моделях часто приближается к 2, что характерно для
действительно случайных последовательностей. h-тест используется для больших выборок и имеет вид:
где При На практике Из закона нормального распределения находим:
Тогда решение выглядит так: a) если
b) если
c) если
Пример: в выборке
Таким образом, с доверительной вероятностью 0.95 можно принять гипотезу о том, что нет позитивной автокорреляции. Особенности h-теста Дарбина: a)
для нахождения значения теста достаточно найти
дисперсию коэффициента предыдущего значения b)
тест нельзя использовать при c) тест можно использовать только для больших выборок, так как свойства теста для маленьких выборок пока еще не определены. |
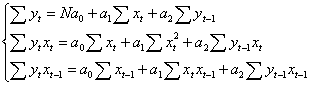
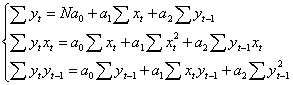
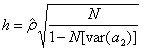 ,
,