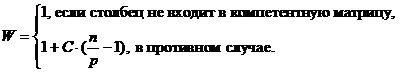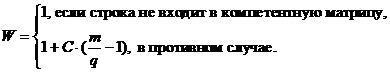|
Алгоритм
ZETBraid |
|||||||||||||||||||||||||||||||||||||||||||||||||
|
Алгоритм ZetBraid [1] является усовершенствованной версией алгоритма
ZET, рассмотренного в предыдущей рассылке [2]. Основным недостатком последнего
является процедура формирования компетентной матрицы, а именно: 1.
Попадание в компетентную матрицу неинформативных строк
или столбцов. 2.
Фиксированность размера
компетентной матрицы. Алгоритм ZetBraid
позволяет избавиться от указанных недостатков путем усовершенствования
процедуры формирования компетентной матрицы методом плетения (англ. braid – плести, плетение). Постановка задачи. Пусть задана
таблица экспериментальных данных Таблица
экспериментальных данных
где Ставится
задача восстановления отсутствующих (пропущенных) значений @ в таблице Алгоритм ZETBraid относится к локальным методам
заполнения пробелов и в основе его функционирования лежат три
предположения (гипотезы): 1.
Гипотеза избыточности: предполагается,
что в таблице 2.
Гипотеза аналогичности: предполагается,
что если два объекта «похожи» по значениям ( 3.
Гипотеза локальной компетентности: предполагается,
что избыточность строк и столбцов носит локальный характер, то есть для каждого
пропущенного значения имеется только некоторое количество объектов – аналогов
объекта с пропуском и свойств – аналогов свойства с пропуском. Поэтому предлагается
использовать для прогнозирования только такие «компетентные» объекты и свойства,
которые выбираются для каждого пропуска отдельно. Рассмотрим основные этапы алгоритма ZET [2]: 1. Предварительная
обработка начальных данных. 2. Прогнозирование
пропуска: 2.1. Формирование
компетентной матрицы. 2.2. Подбор
параметров модели прогнозирования. 2.3. Прогнозирование
пропуска. Алгоритм ZetBraid отличается
только пунктом 2.1, который подробно рассмотрен ниже. Формирование
компетентной матрицы. В
процессе работы алгоритма происходит последовательный поочередный отбор
компетентных строк и компетентных столбцов. При каждом новом отборе строки или
столбца формируется новая компетентная матрица. По заданному критерию
определяется ее эффективность при прогнозировании пропусков. Таким образом,
запишем общий алгоритм формирования лучшей компетентной матрицы для заданного
пропуска: Шаг 1.
Задаем начальный размер компетентной матрицы (обычно берут 3). Это
необходимо для избежания ошибок в начале «плетения». Шаг
2. Определяем самую близкую строку (не входящую в компетентную матрицу)
к целевой строке и добавляем ее в компетентную матрицу. Определяем ошибку
прогнозирования новой матрицы. Если ошибка уменьшилась, то запоминаем
компетентную матрицу, иначе возвращаемся к предыдущей матрице и переходим на
шаг 3. Шаг
3. Определяем самый близкий столбец (не входящий в компетентную
матрицу) к целевому столбцу и добавляем его в компетентную матрицу. Определяем
ошибку прогнозирования новой матрицы. Если ошибка уменьшилась, то запоминаем компетентную
матрицу, иначе возвращаемся к предыдущей матрице и переходим на шаг 2. Если
нельзя добавить ни строку, ни столбец, то конец алгоритма. Для применения
алгоритма необходимо решить следующие
задачи: 1. Определение расстояния
между строками. 2. Определение расстояния
между столбцами. 3. Вычисление критерия
оценки качества компетентной матрицы. 1. Расстояние
между строками вычисляем по формуле
где При вычислении коэффициентов
Если из
2.
Для нахождения расстояния между столбцами необходимо построить уравнение
линейной регрессии. Пусть Для нахождения коэффициентов
где
весовые коэффициенты строк
3.
Критерием оценки адекватности компетентной матрицы есть оценка качества
предсказания неизвестного элемента. Есть
два известных варианта расчета этого критерия. В соответствии с первым, методом
„креста”, по уравнению линейной регрессии рассчитывают все известные значения
строки и/или столбца, которые содержат неизвестный элемент и находят среднюю
ошибку. Эта средняя ошибка и есть оценкой предсказания данной компетентной
матрицы. Второй вариант, дисперсионный метод,
состоит в вычислении дисперсии предсказаний неизвестного элемента. Для этого по
уравнению линейной регрессии для каждого столбца прогнозируют значения неизвестного элемента и находят дисперсию
этих Список
использованных источников 1.
http://www.zetbraid.narod.ru |