|
Возникновение теории информации связывают
с появлением фундаментальной работы американского ученого К.Шеннона
«Математическая теория связи» в 1948 году. Им была предложена, а советским
ученым Л.Я.Хинчиным доказана единственность функционала, который называется
энтропией и имеет вид 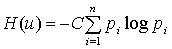 , где , где 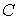 - положительная
константа. Этот функционал указывает на меру неопределенности выбора
дискретного состояния из ансамбля - положительная
константа. Этот функционал указывает на меру неопределенности выбора
дискретного состояния из ансамбля 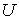 . Если есть . Если есть 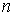 состояний состояний 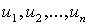 и известны вероятности
этих состояний и известны вероятности
этих состояний 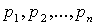 (табл.1), то к мере
неопределенности (табл.1), то к мере
неопределенности 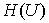 предъявляются следующие требования: предъявляются следующие требования:
Таблица 1

- – непрерывная
функция вероятностей состояний с выполнением условия
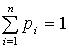 . .
- =
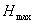 , если , если 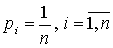 . .
- =
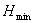 =0,
если =0,
если 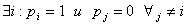 . .
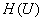 ÎR+ (вещественная, неотрицательная
функция). ÎR+ (вещественная, неотрицательная
функция).- H(XÈY) =H(X)+H(Y), если X и Y статистически независимы.
- Энтропия характеризует среднюю неопределенность
выбора одного состояния из ансамбля.
Меру снятой неопределенности
называют количеством информации 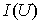 и вычисляют как
разность и вычисляют как
разность 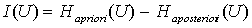 , где , где 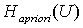 - энтропия до
проведения опыта, - энтропия до
проведения опыта, 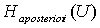 - после проведения
опыта. может
быть как положительным так и отрицательным. - после проведения
опыта. может
быть как положительным так и отрицательным.
Напомним, что в качестве исходных данных
имеем табл.2.
Таблица 2
 Чем более информативными
есть обучающие образы-элементы вектора Чем более информативными
есть обучающие образы-элементы вектора 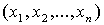 , тем качество предска-занного значения , тем качество предска-занного значения 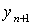 будет большим. будет большим.
Поскольку элементы векторов в общем случае
разноразмерны, то необходимо привести их к единой шкале. Это необходимо
для адекватного применения математических методов и компьютерных расчетов при
вычислениях, связанных с большими и малыми величинами, а также для того, чтобы
установить соответствие между количественными и качественными характеристиками
данных. Например, как Вы ответите на вопрос: «Что более свойственно человеку:
иметь 60 кг веса, или 165 см роста, или 25 лет ?». А
между тем, ответы на вопросы такого типа и их комбинации важны при оценке
склонности человека к определенным заболеваниям.
Еще одним
шагом, дающим возможность сравнения, является нормирование. Основными
формулами, реализующими и приведение к единой шкале, и нормирования есть такие:
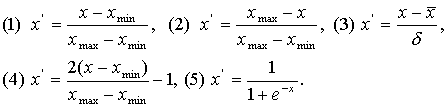
Дадим им
краткую характеристику:
- Область значений – [0,1]. Оптимально использовать, если значения исходных
данных равномерно заполняют интервал изменения. Для некоторых методов
прогнозирования формула неэффективна, если значения будут нулевыми или
сосредоточенными возле концов отрезка [0,1].
- Аналогична первой.
- Третья формула отличается тем, что значения,
полученные в результате ее применения являются безразмерными, в
большинстве своем находящиеся в окрестности нуля, но не обязательно
принадлежат конкретному отрезку.
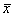 - выборочное среднее значение, d
- выборочное среднее квадратичное отклонение. Из-за неопределенности
границ отрезка изменения значений возникают проблемы соответствия
активационным функциям в искусственных нейронных сетях. Необходимы
дополнительные преобразования, например: - выборочное среднее значение, d
- выборочное среднее квадратичное отклонение. Из-за неопределенности
границ отрезка изменения значений возникают проблемы соответствия
активационным функциям в искусственных нейронных сетях. Необходимы
дополнительные преобразования, например:
Последнее преобразование, кроме значений принадлежащих [0,1],
гарантирует и
более
равномерное распределение значений.
- Область значений – [-1,1]. Формула удобна для
прогнозирования с помощью нейронных сетей, в которых используется в
качестве активационной функции гиперболический тангенс. Имеет все свойства
функций 1 и 2.
- Область значений – (1;+¥).
Редко используется и, в основном, для преобразования отрицательных чисел в положительные. Функция вспомогательная, не
нормировочная и не избавляющая от размерности.
В общем случае, будем считать, что использование
нормировочных функций ведет к отображению входных значений в единичном
гиперкубе. Если они будут сосредоточены в небольшой гиперокрестности, то такие
данные малоинформативны и прогнозирование будет неточным (см.рис.1).
Наибольшей информативностью (в смысле
получения более точного прогноза) будут обладать данные, имеющие равномерное
распределение (известно, что они имеют наибольшую энтропию) (см. рис.2).
Таким образом, одна из главных задач
после приведения к безразмерным величинам и нормализации будет максимизация
энтропии. Об этом будет далее…
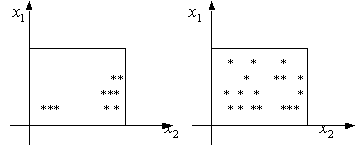
Рис. 1.
Рис. 2.
|

